近日,人工智能研究院朱松纯、朱毅鑫教授团队在IJCV 2022发表论文《Scene Reconstruction with Functional Objects for Robot Autonomy》,提出了一个全新的场景重建问题和场景图表征,为机器人自主规划提供必要的信息,并为其仿真测试提供了与现实场景功能相近的可交互的虚拟场景。同时,这一工作也开发了一个完整的机器视觉系统,以实现所提出的场景重建问题。实验证明了所提出的场景重建方法的有效性,以及场景图表征在机器人自主规划方面的潜力。
感知三维环境并理解其中包含的信息是人类智能的重要体现,也是人类与环境随心交互的前提。在环境的几何特征与物体的语义信息之外,我们还能“感知”到与环境的潜在交互方式,我们称之为环境中动作信息(actionable information)。例如,当我们看到图1(a) 中的门把手时,我们脑海里会自然地出现转动门把手并拉开门的潜在动作,而在图1(b) 的场景里,我们能够轻松地观测到堆叠的茶杯和碗碟的约束关系(相互支撑),以及不同的动作对它们状态的影响(直接抽取下面的碗碟会打翻上面碗碟和茶杯,而逐一移走最上面的物体后则可以安全地拿取下面的碗碟)。理解潜在动作对场景的影响,构成了我们在场景中执行任务并与之交互的基础。相应地,智能机器人也需要类似的感知能力,才能使其在环境中自主地完成复杂的长时程(long-horizon)规划。


图1 (a) 门把手,(b) 堆叠的茶杯和碗碟(图片来源于网络,版权归原作者所有)
随着三维场景重建(3D scene reconstruction)与语义建图(semantic mapping)技术渐趋成熟,机器人已经能够有效地建立包含几何与语义信息的三维地图,例如包括物体与房间结构的语义全景地图(panoptic map),如图2(b)。然而这些传统场景重建的场景表征(scene representation)与实现机器人自主规划之间,仍然有难以逾越的鸿沟。那么问题来了,我们如何能构造一种通用于机器人感知(perception)和规划(planning)的场景表征,以提高机器人的自主规划能力呢?机器人如何能利用自身传感器输入(例如RGB-D相机)在真实场景中建立这样的场景表征?
在这篇论文[1]中,研究人员提出了一个全新的研究问题:重建与现实场景功能相同的(functionally-equivalent)、可交互的(interactive)虚拟场景,以保留原场景的潜在动作信息。重建后的虚拟场景可以被用于机器人自主规划的仿真训练与测试。为实现这一重建任务,研究人员提出了一种基于物理支撑(supporting relation)与紧邻(proximal relation)关系的场景图表征,如图2(a);它的每个节点代表场景中的一个物体或者一种房间结构(墙/地面/房顶)。这一场景图表征将重建后的场景以及其中包含的物理约束有机组织起来,以保证得到的虚拟场景是符合物理常识的。同时,它可以直接被转换成环境的树状运动链(kinematic tree),完整地描述了环境的运动学关系状态,并支持前向预测机器人动作对环境的影响,可被直接用于机器人规划任务中。这篇论文也提出了一个完整的机器视觉系统来实现这一重建任务,并为重建后的场景设计了输出接口,使其能够被无缝接入机器人仿真器(例如Gazebo)和VR环境中。这一论文的部分前期工作[2]曾发表在ICRA 2021上。
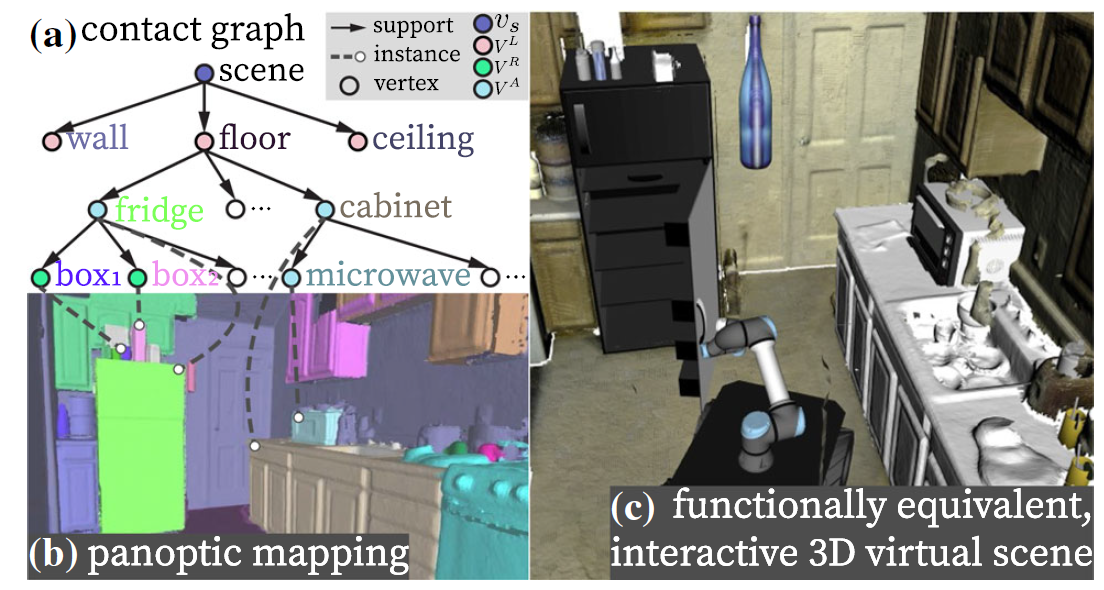
图2(a) 基于支撑与紧邻关系的场景图,(b) 体积式语义全景建图,(c) 与现实场景功能相同的、可交互的虚拟场景,可用于机器人自主规划的仿真测试
在虚拟环境中重建真实场景以支持机器人仿真并非一个简单的问题。主要的难点有三:一是如何在杂乱的真实场景中准确重建并分割出每个物体与结构的几何,并估计物体间的物理约束(比如支撑关系等);二是如何将重建出的不完整的几何形状替换成完整的、可交互的物体(例如CAD模型);三是如何将所有的这些信息有机融入某种通用的场景表达,同时帮助场景重建和机器人自主规划。
这项工作提出利用一种特殊的场景图作为连接场景重建与机器人交互的桥梁,在帮助重建出符合物理常识的虚拟场景的同时,为机器人自主规划提供必要的信息。一方面,这一场景图将场景中感知到的物体、房间结构以及它们之间的关系组织起来,如图3(a) 所示。它的每个节点代表识别并重建出的真实场景中的物体或者房间结构,包括了它的几何(例如重建出的三维网格(mesh)、三维最小包围盒、提取出的平面特征等)与语义信息(如实例与语义标签);而每条边则表示节点之间的支撑关系【见图3 (a) 中的有向边】或者紧邻关系【图3 (a)中的无向边】,代表着某些物理约束信息。比如对支撑关系来说,父节点需要包含水平的支撑面来实现对子节点的稳定支撑;再如对紧邻关系来说,相互接近的两个节点的三维几何不应该有相互的重叠等。另一方面,根据语义与几何的形似性并综合考虑节点间的约束,图3 (a) 中的节点被替换成几何完整的、可交互的CAD模型【包括多关节(articulated)的CAD模型】,进而得生成可用于机器人仿真交互的虚拟场景,如图3 (b)。这样的虚拟场景在感知能力允许的范围内尽可能保留了真实场景的功能(functionality),也就是潜在动作信息,可以有效实现对现实场景中与物体交互结果的仿真。而相应地,得到的场景图表征也包含了对环境运动学以及约束状态的完整描述,可用来预测机器人动作对运动学状态的短期定量影响并帮助机器人运动规划,以及估计机器人动作对约束关系造成的长期定性影响并支持机器人任务规划。
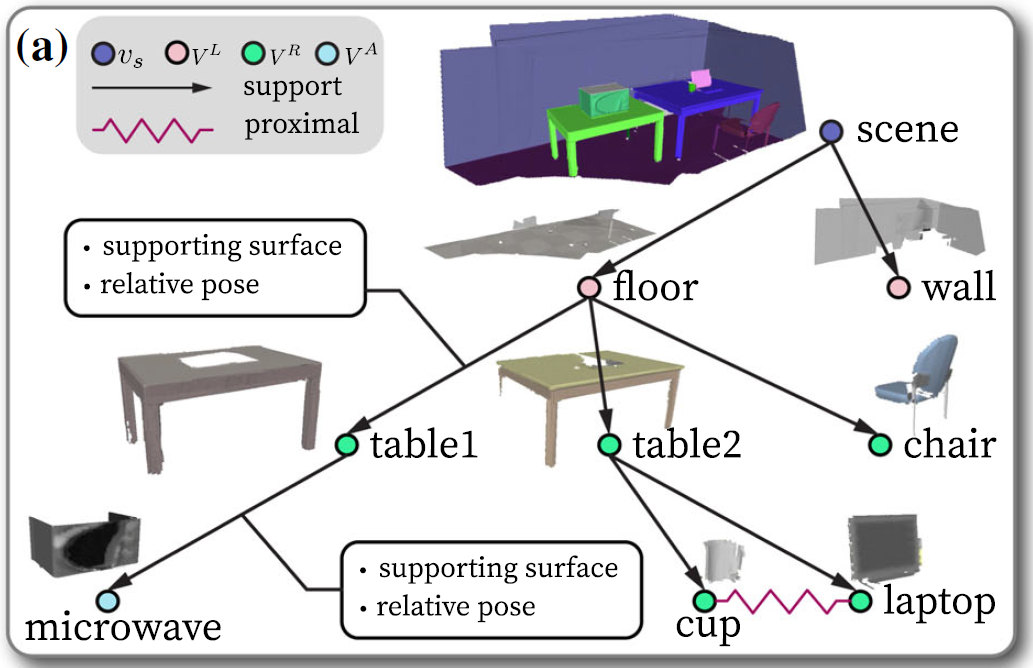
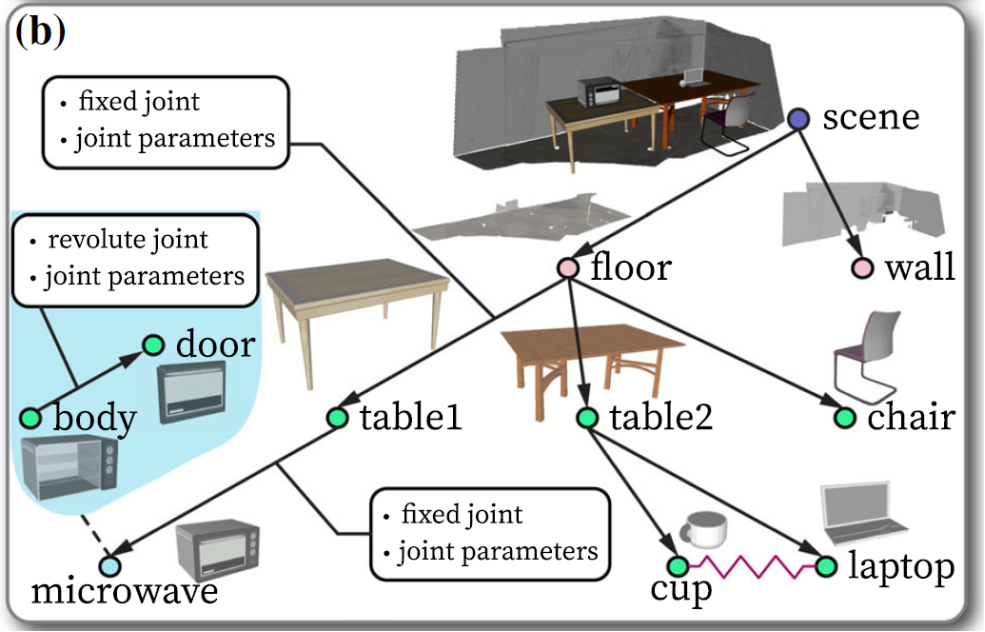
图3 (a) 直接重建出的场景图,(b) 替换CAD模型后的可交互场景图
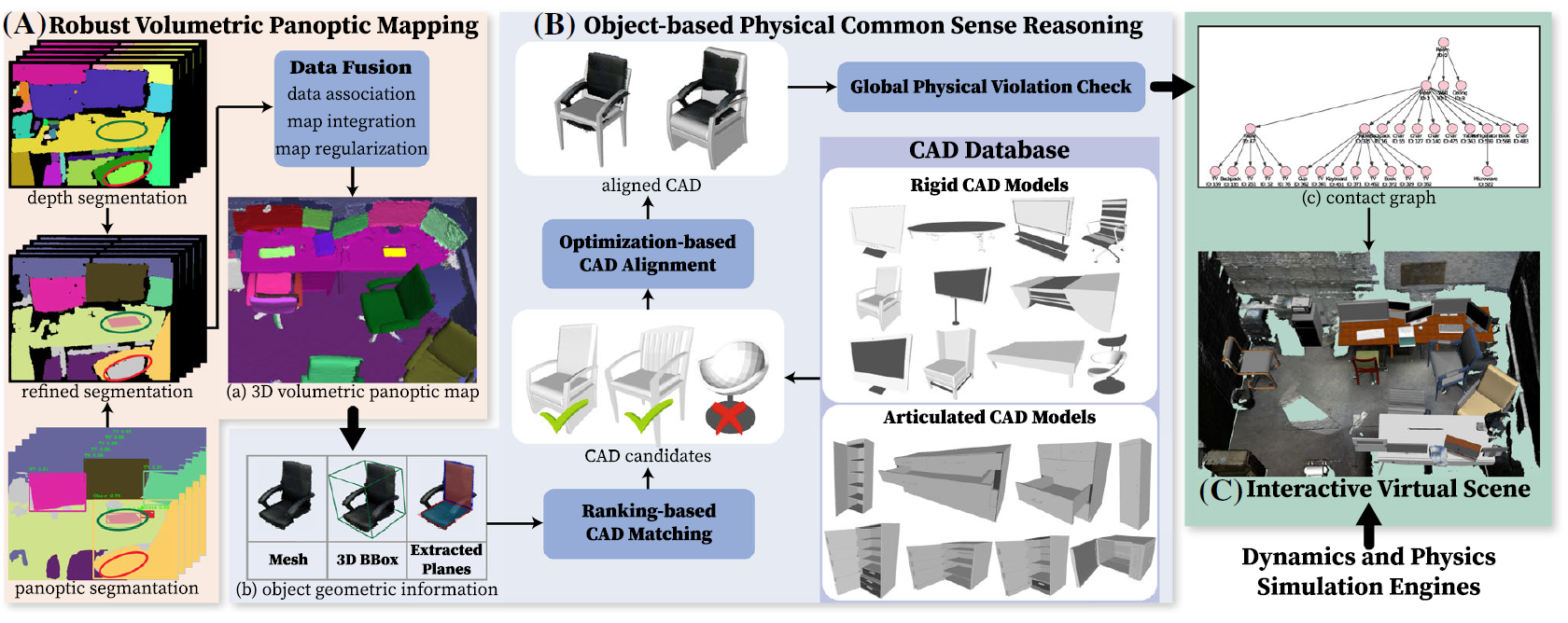
图4 用于重建任务的机器视觉系统流程图
为实现上述的重建任务,论文作者设计并实现了一个多模块的机器视觉系统:一个体积式语义全景建图模块【图4 (A)】,和一个基于物理常识与几何的CAD模型替换推理模块【图4 (B)】。前者被用于鲁棒地在复杂真实环境中借助RGB-D相机识别、分割并重建出物体与房间结构的稠密几何,并估计它们之间的约束关系,以得到如图3 (a) 中的场景图;而后者聚焦于如何根据重建物体的几何特征与识别出的约束关系从CAD模型库中选择最合适的CAD模型,并估计其位姿与尺度,以达到与原物体尽可能准确的对齐,进而生成图3 (b) 所示的可交互的场景图。图5展示了论文作者借助Kinect2相机对真实办公室场景的重建结果,包括体积式全景重建【图5 (a)】、可交互虚拟场景常见【图5 (b) 】以及将虚拟场景导入机器人仿真器后机器人交互的样例【图5 (c)】。我们可以看到,即使在复杂、多遮挡的真实场景中,论文提出的重建系统能较好地建立可交互的虚拟场景。图5 (d-f) 展示了这一实验中的一些有趣的例子:图5 (d) 中,由于椅子对桌子的遮挡,同一个桌子被重建成两个相对短小的桌子;图5 (e) 展示的工位得到了比较高质量的重建,所有的物体都被替换成了外表相近的CAD模型;图5 (f) 中的椅子未能被识别出来,其对后面桌子的遮挡造成了与图5 (d) 相似的情况,而场景中的冰箱与微波炉被重建出来并替换成了多关节、可承载复杂交互的CAD模型。

图5 在真实环境中用Kinect2相机的重建结果

图6 在重建的虚拟场景中的机器人任务与动作规划
在重建得到的可交互虚拟场景里,借助场景图反映的运动链以及约束信息,机器人可以进行任务与动作规划[3,4],其仿真效果如图6所示。在最近的相关的工作[5]中,基于上文所述的场景图表征,机器人可以直接根据图编辑距离(graph editing distance)进行复杂的任务规划,并高效地生成动作。
这项工作提出了一个全新的场景重建问题和场景图表征,为机器人自主规划提供必要的信息,并为其仿真测试提供了与现实场景功能相近的可交互的虚拟场景。同时,这一工作也开发了一个完整的机器视觉系统,以实现所提出的场景重建问题。实验证明了所提出的场景重建方法的有效性,以及场景图表征在机器人自主规划方面的潜力。
未来,我们期待这项工作的进一步拓展:如何更鲁棒、更精准地实现刚体与多关节CAD模型与重建几何的匹配、如何在场景图中融合更复杂的潜在动作信息、以及如何更好地利用场景提进行机器人规划。场景图重建助力自主规划,更智能的机器人就在不远的将来。
参考文献:
[1] Han, Muzhi, et al. “Scene Reconstruction with Functional Objects for Robot Autonomy.” 2022 International Journal of Computer Vision (IJCV), link.springer.com, 2022.
[2] Han, Muzhi, et al. “Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments.” 2021 IEEE International Conference on Robotics and Automation (ICRA), ieeexplore.ieee.org, 2021, pp. 12199–206.
[3] Jiao, Ziyuan, et al. “Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations.” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, doi:10.1109/iros51168.2021.9636351.
[4] Jiao, Ziyuan, et al. “Efficient Task Planning for Mobile Manipulation: A Virtual Kinematic Chain Perspective.” 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), ieeexplore.ieee.org, 2021, pp. 8288–94.
[5] Jiao, Ziyuan, et al. “Sequential Manipulation Planning on Scene Graph.” 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), ieeexplore.ieee.org, 2022.


